After that, we require to handle HTML tags to locate all the links within the page's tags and the appropriate table. Afterwards, iterate through each row and after that appoint each element of tr to a variable as well as append it to a list. If you are still confused regarding how to get started with data crawling, the video listed below should drop some light on it. As you do more internet scratching, it is essential to consider the moral effects of crawling sites and just how to do it properly.
- They can draw info on resort prices, existing supply prices, listings of realty, etc.
- The net is an ocean of details that is commonly not easily accessible through an API, which can offer restricted access to the data or not also be available.
- Internet crawling is a powerful technique to gather information from the web by discovering all the URLs for one or numerous domains.
- You will certainly learn to utilize CSS selectors and also XPath expressions to draw out meaningful information from HTML papers.
- Free Android proxy manager application that collaborates with any kind of proxy provider.
This command develops a new project with the default Scrapy project folder structure. To run our crawler, merely enter this command on your command line. A fundamental spider can be built complying with the previous design diagram.
Make The Most Of User Representatives
Abigail Jones Today, big information has been widely utilized in various areas like e-commerce websites, social media sites, clinical reforms and also financial reports. Although there are many data organizations to provide different databases, unique needs are not usually thought about by such companies. People or business want even more details like the particular price of the item or the call details of various internet sites. That may be the ground of the site information scuffing solution. You might currently discover there are several website information removal devices readily available online like Import.io and Octoparse.
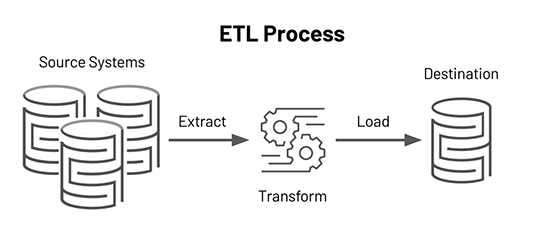
What is the distinction between creeping and searching?
A crawler is a computer program that scans files on the internet instantly. Crawlers are primarily configured to make sure that surfing is automated for repeated actions. Online search engine use crawlers most often to surf the Web and also develop an index.
We import its plan right into our job and also develop a circumstances of it named crawlerInstance. In the snippet above, we send out a message to the parent string making use of parentPort.postMessage() after booting up a worker thread. Then, we listen for a message from the parent thread using parentPort.once(). You have actually effectively removed data from that initial page, however we're not advancing past it to see the remainder of the outcomes. The whole point of a spider is to spot and also traverse links to various other web pages and get hold of information from those web pages also. Currently let's turn this scrape into a crawler that adheres to web links.
Browserless Configuration
Our data listing currently consists of a thesaurus containing crucial information for every single row. In the loophole we can combine any multi-step removals right into one to create the worths in the least number of actions. The only class we required to use in this situation was.source-title since.views-field looks to be simply a course each row is offered for designing and does not give any individuality. There's an interesting web site called AllSides that has a media predisposition score table where customers can agree or disagree with the rating. I conserve almost every page as well as parse later when web scratching as a security preventative measure. To recover our saved documents we'll make an additional function to cover reviewing the HTML back into html.
The previous phase showed numerous techniques of crawling with internet sites and also discovering new web pages in an automated means. However, I believe that the power and also relative versatility of this method greater than makes up for its genuine or regarded imperfections. Nonetheless, the information version is the underlying foundation of all the code that uses it. An inadequate choice in your design can quickly bring about problems creating as well as preserving code down the line, or difficulty in drawing out and also effectively using the resulting information.
Usage Situations: Web Creeping Vs Web Scuffing
Currently, if you conserve your code as well as run the spider once more you'll see that it does not simply quit when it iterates via the first web page of collections. In the grand scheme of points it's not a substantial portion of information, today you recognize the procedure by which you automatically locate new web pages to scratch. These sorts of things will certainly be resolved later on when we construct extra intricate scrapes, but feel free to let me know in the remarks of anything in particular you're interested in finding out about. Currently, data is a list of dictionaries, each of which includes all the information from the tables as well as the web sites from each private news resource's web page on AllSides. On Apify Store you can try numerous existing internet scratching options free of charge. As a following step, you can use Apify's Python API Customer to access the result data from those ready-made solutions and after that process it making use of Python's extensive collection of information manipulation libraries.
- As a result, Python boasts several of the most prominent internet scraping libraries as well as frameworks, such as BeautifulSoup, Selenium, Dramatist, and also Scrapy.
- Depend on wise IP address rotation with human-like internet browser fingerprints.
- Customer agents allow the server you intend to scuff to comprehend which web browser, running system, or tool you are using.
- Internet crawling is used for information extraction and refers to gathering information from either the net or, in data creeping situations-- any paper, file, etc.
- After the removal of the data, it is after that exchanged the layout chosen by the writer of the scraper bot.
- Also, the simple web scratching tool to help you gather data without any coding abilities.
Just bear in mind that in a lot of these instances, it will imply internet scraping/crawling as opposed to data scraping/crawling, turning a blind eye to their exact interpretations. The brief version is that web scuffing has to do with drawing out the ETL Processes information from several websites. Information scratching is simpler to set up, as it can be personalized to complete any specific task as well as overcome any potential obstacles that might happen while doing so.
Begin With Octoparse Today
Free Chrome proxy manager extension that deals with any kind of proxy carrier.
https://maps.google.com/maps?saddr=433%20Yonge%20St%202nd%20Floor%2C%20Toronto%2C%20ON%20M5B%201T3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
LogRocket tools your application to tape-record baseline performance timings such as page lots time, time to initial byte, sluggish network requests, as well as likewise logs Redux, NgRx, and Vuex actions/state. Crawlee is written in Typescript, as well as it likewise uses Playwright and Puppeteer. Web Scraping Because Playwright and also Puppeteer offer headless-browser performances, this indicates that you can scrape vibrant web pages. With rateLimit set to 2000, there will be a 2 second void between demands. It enables us to extract elements from HTML making use of the jQuery selector phrase structure($). OK, the Scraper wont run if you neglect to include import scrapy to the first line of code.
Meta's new Twitter rival app Threads gets 10 million sign-ups within ... - Charleston Post Courier
Meta's new Twitter rival app Threads gets 10 million sign-ups within ....
Posted: Thu, 13 Jul 2023 02:00:55 GMT [source]
What is the distinction in between ditching and also crawling?
Web scraping goals to draw out the information on website, as well as internet crawling objectives to index as well as find websites. Web crawling includes complying with links completely based on links. In comparison, web scuffing indicates writing a program computing that can stealthily gather data from several websites.